
SAP HANA DB

Die SAP HANA DB ist das aktuelle Datenbank-Produkt von SAP und gehört zur SAP Business Suite 4 SAP HANA. Im Gegensatz zu SAP R/3 und ERP 6.0 wird in Zukunft bei SAP Produkten, wie S/4HANA, nur noch die HANA DB unterstützt. Daher müssen sich langfristig auch alle Kunden anderer Datenbanken ("anyDB") mit der SAP HANA DB auseinandersetzen.
Was ist SAP HANA DB?
Entwickelt wurde die Datenbanktechnologie SAP HANA DB (früher “High Performance Analytic Appliance” genannt) von dem Hasso-Plattner-Institut zusammen mit SAP und der Universität von Stanford. Sie stützt sich auf die Idee der In-Memory-Datenbanken, die alle Inhalte spaltenweise im RAM halten und durch bessere Performance überzeugen. Die Zugriffsgeschwindigkeit ist dabei bis zu 100.000-mal schneller als bei einer Festplatte.
Sie suchen Unterstützung durch SAP Basis Berater? Wir bieten mehr als nur einen gewöhnlichen Berater auf Zeit. Informieren Sie sich über Ihre Vorteile!
RAM ist also ein sehr schnelles Speichermedium. Dadurch ist es erstmals möglich, große Datenmengen in Echtzeit zu analysieren. Dies ist beispielsweise dann wichtig, wenn die Daten aus unterschiedlichen Quellen stammen und im Anschluss in einem Datenbank-Management-System (DBMS) zusammengefügt werden müssen. Dadurch werden Anwender bei ihrer Entscheidungsfindung interaktiv unterstützt.
Außerdem verschwindet die Unterscheidung zwischen Online Transaction Processing (OLTP) und Online Analytic Processing (OLAP),. Zudem werden transaktionale und analytische Funktionen mit Hilfe der In-Memory-Technologie in einem System verarbeitet.
Unterscheidung der HANA-Begriffe
Bei der Veröffentlichung von SAP HANA im Jahr 2011 war der Grundgedanke, eine spaltenorientierte In-Memory-Datenbank bereitzustellen, die HANA DB. Mit ihr konnten komplexe Anfragen mit einer sehr hohen Geschwindigkeit verarbeitet werden. Somit kommt es zu einer Beschleunigung von Geschäftsprozessen sowie einer Vereinfachung der IT-Infrastruktur.
Im Jahr 2013 folgte die HANA Platform, welche Datenbankdienste, Integrationsdienste sowie Verarbeitungsdienste und Applikationsdienste. Sie dient als Basis für das Kernprodukt S/4HANA (ERP), welches im Jahr 2015 veröffentlicht wurde. S/4HANA ist das aktuelle ERP-System der SAP und verfügt über intelligente Technologien, wie maschinelles Lernen und künstliche Intelligenz, sodass erweiterte Analysen möglich sind. Weiterhin zeichnet sich SAP durch ein vereinfachtes Datenmodell und einen überabeiteten, auf HANA angepassten Programmcode aus. Darüber hinaus steht dem Anwender für die meisten Prozesse eine nach den SAP Fiori-Richtlinien entwickeltes User Interface (UI) zur Verfügung.
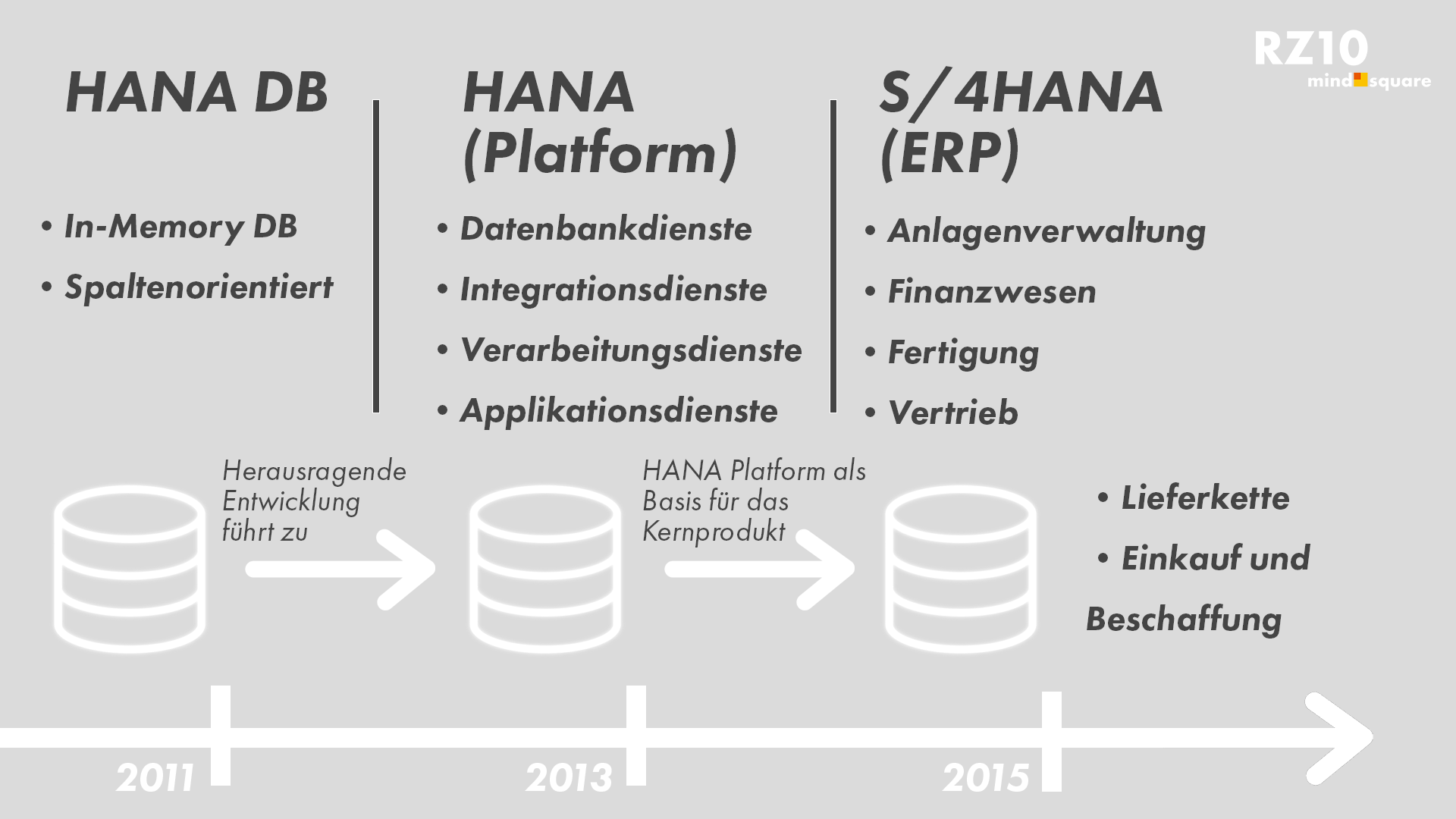
Abgrenzung der HANA Begriffe
Architektur
Die HANA DB zeichnet sich durch ihre In-Memory-Technologie aus. Bei dieser Methode werden betriebswirtschaftlichen Daten nicht auf Festplatten gespeichert, um mit Indizes auf sie zugreifen zu können. Stattdessen werden sie im Arbeitsspeicher gehalten, damit sie möglichst in Echtzeit vorliegen. Als Ergänzung zu SAP Business-Suite-Systemen können bestimmte Rechen- oder Analyseaufgaben an eine separat betriebene SAP HANA DB ausgelagert werden (side-car-Architektur). Zu Beginn war die HANA DB auch ausschließlich als Appliances (Software/Hardware-Bundle) verfügbar – mittlerweile kann die Software aber auch auf geeigneter Hardware installiert werden. Die SAP HANA DB benötigt viele Ressourcen und es sollte ausschließlich auf zertifizierter Hardware verwendet werden.
Wichtig ist auch, dass die HANA DB zwar als Backend-Datenbank hinter einem ABAP-Application-Server eingesetzt werden kann, die aktuellen Versionen aber einen vollständigen eigenen Application Stack bietet (SAP HANA XS Advanced Runtime Platform, XSA).
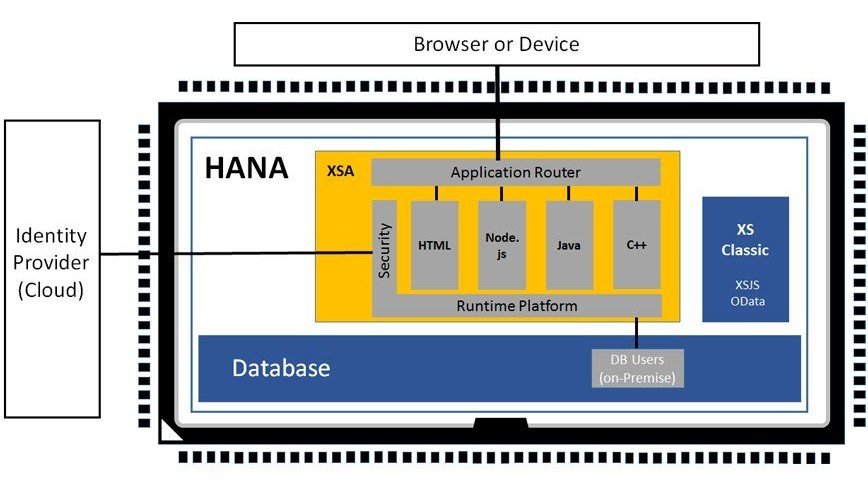
SAP HANA XS Advanced Runtime Platform
Das bedeutet, es ist auch möglich Applikationen auf der HANA DB zu entwickeln und bereitzustellen. Dabei ist es dann allerdings notwendig, Themen wie Benutzer- und Berechtigungsmanagement auf der Datenbank abzubilden. Die SAP Enterprise Threat Detection kann als ein beispielhaftes Produkt genannt werden, das als Applikationen auf HANA DB abgebildet ist.
Einsatzbereiche
Derzeit verwendet SAP die HANA DB bei unterschiedlichen Einsatzfeldern, damit sie aus den Eigenschaften der HANA DB betriebswirtschaftlichen Nutzen ziehen können. In Stand-Alone-Szenarien können beispielsweise spezielle Analyse-Aufgaben mit einer signifikant besseren Performance als zuvor erledigt werden. Häufig ist die Einführung der HANA DB in dem Bereich SAP Business Intelligence (SAP BI/SAP BW) ein Einstiegsprojekt, da es in bestehenden SAP Landschaften den besten Nutzen bringt. Diese Beschleunigung eines OLAP Systems war eigentlich nicht das zentrale Thema der HANA Technologie. Nichtsdestotrotz sind bedeutende Performancegewinne möglich, ohne die Systemarchitektur grundsätzlich zu verändern.
Unterschied zwischen der HANA DB und einer Any-DB – In-Memory
Durch kostengünstige Hauptspeicher mit zunehmenden Kapazitäten ist es für einen schnelleren Zugriff sinnvoll, immer mehr Daten im Hauptspeicher zu puffern. Falls nun aber alle Daten auf diese Weise abgelegt werden, erhält man einen zentralen Punkt in der In-Memory Technologie. Daraus können zahlreiche Konsequenzen und Probleme resultieren.
Da die Größe von allen Geschäftsdaten einer Applikation im mehrstelligen Terabyte Bereich liegen kann, sind geeignete Komprimierungsverfahren notwendig. Um einen schnellen Zugriff über eine Anwendung zu gewährleisten, sollten die dazu benötigten Informationen im Speicher nahe zusammen liegen. Dadurch soll im Sinne der Datenlokalität die Zahl der Seitenfehler im Cache verringert werden.
Wegen der veränderten Zugriffsweise durch analytische Prozesse gibt es nun die Idee, das Seitenlayout von Datenbanktabellen in HANA zu übertragen. Im zeilenbasierten Layout mussten die einzelnen Zeilen der Tabelle hintereinandergeschrieben werden und die Spalten der Tabelle zerschnitten werden. Durch das spaltenbasierte Layout ist es nun so, dass die einzelnen Spalten zusammenbleiben und hintereinander weggeschrieben werden. Dadurch erhält man wiederum neue Angriffspunkte für die zwingend erforderliche Komprimierung.
Spaltendekomposition
In der Datenbank wird jede Spalte durch einen Attribut- und Dictionary-Vektor repräsentiert. Das Dictionary beinhaltet dabei in sortierter Weise die unterschiedlichen Werte der Spalte. Die Positionen der Werte im Dictionary-Vektor werden im Attributvektor weggeschrieben.
Auf das Dictionary und den Attributvektor können nun geeignete Komprimierungen vollzogen werden. Oft schwankt der erzielte Komprimierungsfaktor wie z.B. das Verhältnis aus komprimierter und unkomprimierter Speichergröße in typischen Anwendungen je nach Spalte zwischen 20 und 140 Prozent. Allerdings ist das Gesamtergebnis zumeist wesentlich vorteilhafter.
Ein zusätzlicher zentraler Vorteil des spaltenbasierten Layouts für analytische Berechnungen ist die deutliche Verbesserung einer möglichen Parallelisierung. So können damit z. B. mehrere Spalten unabhängig voneinander aggregiert werden. Weiterhin wird mit diesem Vorgehen für weniger Speicherverbrauch gesorgt, wodurch wiederum ein Vorteil bezüglich der Performance entsteht.
ACID-Kriterien und Datenerhaltung in HANA
Wie bereits erwähnt, werden die Daten einer In-Memory-Datenbank im flüchtigen Hauptspeicher abgelegt. Die Daten können im RAM jedoch nicht dauerhaft abgespeichert werden, da ein Stromausfall oder ein Neustart zum Verlust aller Daten führen würde. Hier kommen die ACID-Kriterien zum Einsatz. Sie beschreiben die gewünschten Eigenschaften eines verlässlichen Datenbanksystems. Das Wort ACID setzt sich aus den Begriffen Atomarität, Konsistenzerhaltung, Isolation und Dauerhaftigkeit zusammen:
- Die Atomarität einer Transaktion ist vorhanden, wenn bei einem einzigen Teilfehler die komplette Transaktion als fehlerhaft eingestuft wird und somit keine Änderungen in der Datenbank vorgenommen werden.
- Unter Konsistenzerhaltung versteht man die Prüfung der eingegebenen Daten bezüglich der Einhaltung geltender Richtlinien. Demnach sollen nur valide Daten in die Datenbank übernommen werden. Andernfalls wird die Transaktion als ungeschehen angesehen und die Daten werden in den vorherigen Zustand versetzt.
- Die Isolation von Transaktionen soll gewährleisten, dass eine zeitgleiche Änderung der gleichen Daten durch unterschiedliche Transaktionen verhindert wird.
- Als letztes muss im Rahmen der Dauerhaftigkeit dafür gesorgt werden, dass die in der Datenbank übernomme Daten dauerhaft dort gespeichert bleiben. Auch wenn die HANA Datenbank eine spaltenorientierte In-Memory-Datenbank ist, müssen die ACID-Kriterien erfüllt sein.
Umstieg auf HANA DB
Bereits vor einigen Jahren hat SAP festgelegt, dass HANA die zukünftige Standardtechnologie für SAP-Produkte sein wird. Deshalb sind Unternehmen, die sich zukunftssicher aufstellen wollen, mit HANA auf dem richtigen Weg. Auch gibt es Laufzeit-Beschränkungen in den Verträgen zwischen SAP und anderen Datenbankherstellern. Das bedeutet, dass Nutzer, die nach 2025 auf ERP 6.0 bleiben wollen, in Zukunft zumindest auf ERP 6.0 on HANA DB umsteigen müssen, weil die Nicht-SAP-Datenbanken ab dann nicht mehr unterstützt werden.
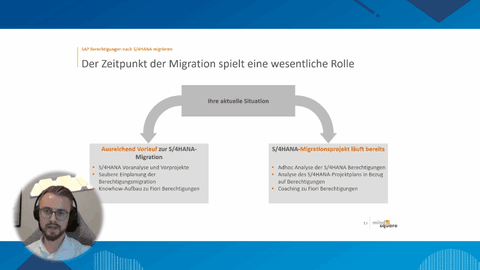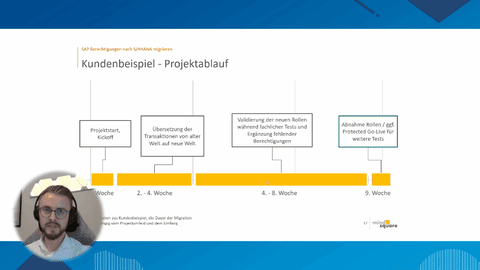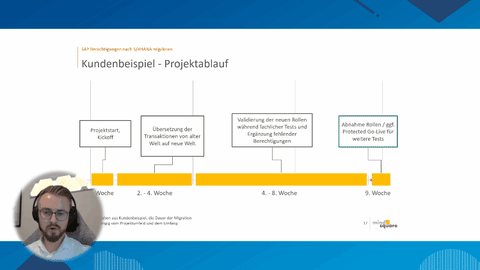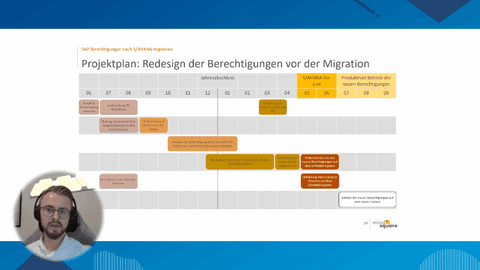
Das stärkste Argument für einen Umstieg auf die HANA DB ist jedoch die deutlich schnellere Rechenleistung. Diese macht Analysen möglich, die bisher zu lange gedauert hätten und damit zu kostspielig gewesen wären. Mit Hilfe der HANA DB schafft man sich folglich Wissens- und damit Wettbewerbsvorteile.
Falls eine bestehende SAP-Infrastruktur auf die HANA DB migriert wird, gilt folgendes Prinzip: Einige Programme laufen schneller, andere bleiben gleich und wieder andere laufen langsamer als bisher. Da allerdings immer mehr speziell für SAP HANA-optimierte Anwendungen ausgeliefert werden, ist zukunftsorientiert die SAP HANA DB sinnvoll, denn diese Programme nutzen dann die Performancevorteile von HANA optimal aus.

Integration von SAP HANA DB in der Cloud
Die Integration von SAP HANA DB in Cloud-Umgebungen bietet Unternehmen vielfältige Möglichkeiten, ihre Datenbanklösungen effizient zu gestalten und die Vorteile der Cloud-Technologie optimal zu nutzen. Eine besonders interessante Option zur Integration ist die Nutzung der SAP HANA Cloud. Diese umfassende Plattform ermöglicht eine nahtlose Verbindung zwischen SAP HANA DB und der Cloud, wodurch Unternehmen ihre Datenbanken in einer skalierbaren, flexiblen und sicheren Infrastruktur hosten können. Durch die Kombination mit anderen Cloud-Services wie Cloud Storage, Big Data Analytics und maschinellem Lernen eröffnen sich zudem neue Wege der Datenverarbeitung und -analyse. Die Skalierbarkeit der Cloud-Plattformen ermöglicht es Unternehmen, ihre Datenbankressourcen bedarfsgerecht anzupassen und so eine optimale Performance sicherzustellen. Darüber hinaus können Unternehmen durch den Einsatz von Multi-Cloud-Umgebungen von den Stärken verschiedener Cloud-Anbieter profitieren und so Redundanz und Ausfallsicherheit erhöhen.
Insgesamt eröffnen die Integrationsmöglichkeiten von SAP HANA DB in Cloud-Umgebungen Unternehmen neue Wege, um ihre Datenbankinfrastruktur zu skalieren, die Performance zu optimieren und innovative Funktionen zu nutzen.
Dieser Artikel erschien bereits im Mai 2023. Der Artikel wurde am 19.09.2025 erneut geprüft und mit leichten Anpassungen aktualisiert.
FAQ
Was ist die SAP HANA DB?
Die SAP HANA DB (früher: High Performance Analytic Appliance) ist das aktuelle Datenbank-Produkt von SAP und gehört zur SAP Business Suite 4 SAP HANA. Im Gegensatz zu SAP R/3 und ERP 6.0 wird in Zukunft bei SAP Produkte wie S/4HANA nur noch die HANA DB unterstützt.
Wo wird die SAP HANA DB eingesetzt?
Derzeit verwendet SAP die HANA DB bei unterschiedlichen Einsatzfeldern, damit sie aus den Eigenschaften der HANA DB betriebswirtschaftlichen Nutzen ziehen können. In Stand-Alone-Szenarien können beispielsweise spezielle Analyse-Aufgaben mit einer signifikant besseren Performance als zuvor erledigt werden.
Weiterführende Informationen
- SAP S/4HANA
- HANA DB mit Eclipse
- Einblick in die SAP HANA Datenbank
- SAP HANA DB
- Server Architecture of SAP HANA XS Advanced Runtime Platform
Wer kann mir beim Thema SAP HANA DB helfen?
Wenn Sie Unterstützung zum Thema SAP HANA DB benötigen, stehen Ihnen die Experten von RZ10, dem auf dieses Thema spezialisierten Team der mindsquare AG, zur Verfügung. Unsere Berater helfen Ihnen, Ihre Fragen zu beantworten, das passende Tool für Ihr Unternehmen zu finden und es optimal einzusetzen. Vereinbaren Sie gern ein unverbindliches Beratungsgespräch, um Ihre spezifischen Anforderungen zu besprechen.











6 Kommentare zu "SAP HANA DB"
Hallo Tobias,
Ich habe ein EHP7 System und eine Oracle DB auf einem Windows Server. Ich möchte gerne auf die HANA DB migrieren. Wenn ich mit DMO die Orale DB auf HANA DB (auf einen Unix Server) migriere, bleibt dann der SAP Application Server (SAP Instance) auf dem Windows Server oder wird der Application Server mitmigriert und man benötigt dafür einen vorinstallierten Unix Server ?
Oder wird mit DMO nur die Datenbank migriert ?
Danke schön
Hallo Tobi,
hier gibt es kein klares Ja oder Nein. Grundsätzlich wird mit der DMO erstmal nur die DB migriert. Es ist aber möglich auch den PAS mit zu migrieren.
Weitere Infos findest du hier: https://blogs.sap.com/2017/05/22/dmo-with-system-move-the-use-case-to-change-pas-host-during-dmo/
Viele Grüße
Hallo Tobias,
für welche Systeme wird eine “Standard System” Installation empfohlen ? Also wenn man die HANA Datenbank und Applikation Server auf einem Server installiert ?
Welche Probleme können auftreten, wenn man die Produktion als ein Standard System (alles auf einem Server) installiert ?
Danke
Hi Beni, es spricht erstmal nichts gegen ein kompaktes System – nur gerät man hier schnell an Leistungsgrenzen und kann schwieriger skalieren. Und Skalierbarkeit ist eine der wichtigen Funktionen von SAP. Daher geht man bei der Systemplanung eher davon aus, dass eine abgesetzte Serverstruktur zwar initial bei der Installation teurer ist. Das wird aber bei dem späteren Betrieb durch leichtere Wartung (Downtime von einem Applikationsserver behindert nicht den Betrieb) wieder wettgemacht.
Liebes RZ10 Team
Ich habe eine Verständnisfrage.
Reserviert eine HANA DB Ihr RAM immer bis zum Allocation Limit (also was im Parameter allocation_limit gesetzt ist) und gibt das nicht mehr an das Betriebssystem zurück ? Ist das richtig ?
Danke
Hi, schwer zu sagen, nach unser Beobachtung ist freier Speicher unter Linux schwierig zu messen. Das allocation_limit gilt normalerweise auch nur für den Tenant. Schau mal hier: 2175606 – HANA: How to set allocation limit for tenant databases