
Umsetzung des ACID-Prinzips mit der HANA DB
Autor: Tobias Harmes | 4. Dezember 2018

Im Unternehmenskontext wird an Datenbanken, speziell in Verbindung mit Enterprise Resource Planning (ERP) Software, das Prinzip von ACID gefordert. Was verbirgt sich jedoch hinter diesem Prinzip und wie wird dies mit der neuen In-Memory-Datenbank (HANA DB) von SAP umgesetzt? Hierfür wird im folgenden Blogbeitrag das Prinzip ACID im Detail erläutert und die Verbindung zur HANA DB gezeigt.
Leitfragen welche im Laufe des Beitrags beantwortet werden sollen sind somit
- Was ist die SAP HANA DB?
- Wofür steht ACID?
- Wie wird das ACID Prinzip bei der SAP HANA DB umgesetzt?
Was ist die SAP HANA DB?
Die SAP HANA (ehemals: High Performance Analytic Appliance) DB ist die neue Datenbank von SAP, gehört zur SAP Business Suite 4 SAP HANA und löst das in SAP R/3 vorhandene Konzept der „any DB“ ab. Das neue SAP S/4HANA kann somit nur noch ausschließlich mit der dazugehörigen SAP HANA DB betrieben werden. Die von SAP, dem Hasso-Plattner-Institut und der Universität von Stanford entwickelte Datenbank basiert auf dem Konzept der In-Memory Datenbanken, welche alle Inhalte spaltenweise im RAM halten und bessere Performance bieten. Durch das arbeiten auf nicht persistenten Speicher Medien stellt sich jedoch die Frage wie die sichere Durchführung von Transaktionen in diesem Umfeld gewährleistet werden kann und eine dauerhafte Speicherung von Daten möglich ist.
Workshop: SAP HANA Roadmap - Ihr Schritt zur Digitalisierung
Wir helfen Ihnen bei der Einführung, Ihrer SAP HANA Roadmap. Von der ersten Analyse bis zur Migration. Jetzt Infos holen!
Wofür steht ACID?
Das Akronym ACID steht ausgeschrieben für die vier Anforderungen und Regeln an Transaktionen in einem Datenbankmanagementsystem um diese zum Beispiel für den Einsatz im betriebswirtschaftlichen Bereich verwenden zu können.
Atomicity (Atomarität)
Die Atomarität einer Transaktion in einer Datenbank wird häufig mit den Worten „ganz oder gar nicht“ beschrieben“. Das heißt das Transaktionen, welche in einem Fehler gelaufen sind, alle vorhergehenden Änderungen in der Datenbank vom System wieder rückgängig gemacht werden müssen. Im Umkehrschluss bedeutet dies, dass Transaktionen erst gültig sind wenn sie komplett und erfolgreich durchlaufen wurden.
Consistency (Konsistenz)
Konsistenz wird vor und nach jeder Transaktion in einem Datenbankmanagementsystem gefordert. Diese Regel zielt auf die Prüfung von eindeutigen Beziehungen, Fremdschlüsseln oder Wertebereiche ab. Kann nach einer Transaktion kein konsistenter Zustand hergestellt werden muss die komplette Transaktion rückgängig gemacht werden. Zu erwähnen ist jedoch das während einer Transaktion inkonsistente Zustände auftreten können, welche jedoch auftreten dürfen.
Isolation (Abgrenzung)
Die Abgrenzung bezieht sich auf den Betrieb eines Datenbankmanagementsystem mit Zugriffen von mehreren Nutzern und dient zur Verhinderung der damit verbundenen Anomalien wie z.B. das löschen oder ändern geänderter Datensätze. Generell sollte jeder Nutzer sich so fühlen als sei er allein auf dem Datenbankmanagementsystem. Häufig wird dies mit Sperren auf Datensätzen realisiert. Da Sperren in Datenbanken und speziell im SAP-Umfeld ein enorm umfangreiches Thema sind wird in diesem Beitrag nicht weiter darauf eingegangen.
Durability (Dauerhaftigkeit)

Nach erfolgreichem Abschluss einer atomaren und konsistenten Transaktion auf einem Datenbankmanagementsystem müssen die Daten dauerhaft gespeichert sein. Sollte zum Beispiel der Server ausfallen müssen die erfolgreich abgeschlossenen Transaktionen im Datenbankmanagementsystem erhalten bleiben und dürfen nicht gelöscht oder erneut eingefügt werden.
Wie wird das ACID Prinzip bei der SAP HANA DB umgesetzt?
Der Persistenz Layer wird während dem Aufsetzen der HANA Datenbank von einem Mitglied des SAP Basis-Teams konfiguriert. Er dient als Schnittstelle zwischen dem persistenten Speicher (Festplatte) und dem flüchtigen Speicher (RAM). Dieser Layer trägt vorwiegend dazu bei, dass in der HANA Datenbank das ACID-Prinzip eingehalten wird. Die wichtigste Aufgabe des Persistent Layers ist das Erstellen der Savepoints, in welchen alle erfolgreich abgeschlossenen Transaktionen gesichert sind. Im Falle eines Absturzes können so die vorhandenen Daten wieder in den Arbeitsspeicher geladen werden. Die Erstellung dieser wird alle X Sekunden (Default 300 sek.) durchgeführt und kann von einem Basis-Mitglied verändert werden, hier zählt natürlich ein gutes Verhältnis zwischen Kosten und Nutzen zu finden.
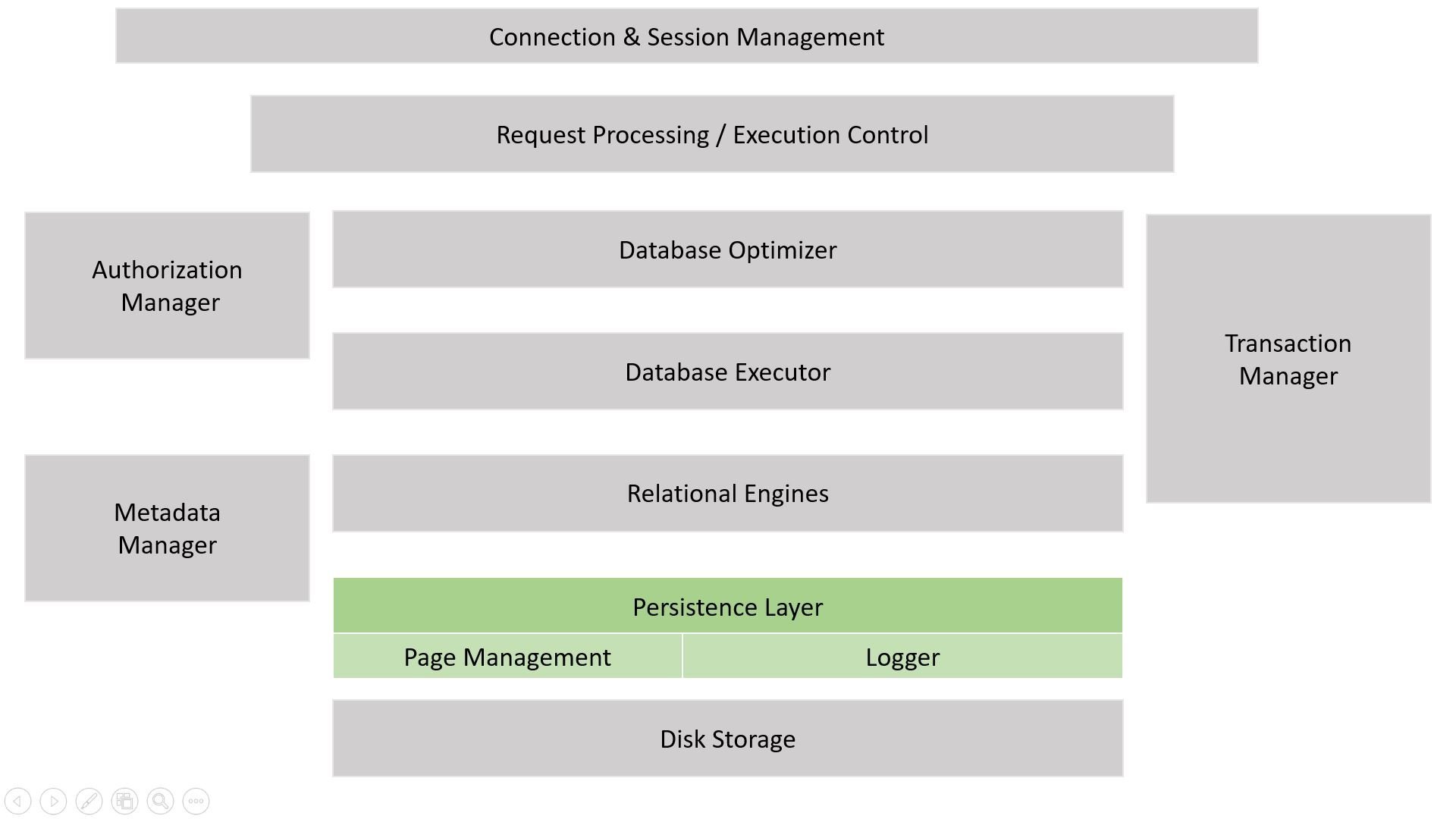
SAP HANA DB Schichten-Modell
Transaktionen welche vor oder während dem Absturz noch nicht als abgeschlossen gegolten haben werden in die sogenannten Redo- und Undo- Logs aufgenommen und nach dem laden des Savepoints wieder auf den bestehenden Datensatz aufgespielt um eine konsistente Datenbank zu erhalten. Im Falle eine abgebrochene oder fehlerhafte Transaktion können so auch wieder alle Änderungen Rückgängig gemacht werden bis die Datenbank in einem konsistenten Zustand ist.
Der Persistenz Layer trägt somit vorwiegend zur Konsistenz und Dauerhaftigkeit der HANA Datenbank bei und ermöglich zugleich noch die Atomarität dieser In-Memory Datenbank.
Haben Sie bereits Erfahrungen mit der Konfiguration der HANA DB gesammelt oder haben eine “best practice” zur Erstellung von Savepoints? Teilen Sie mir gerne Ihre Erfahrungen in der Kommentarbox mit, ich würde mich sehr freuen!





